cv-analysis - Visual (CV-Based) Document Parsing#
parse_pdf() This repository implements computer vision based approaches for detecting and parsing visual features such as tables or previous redactions in documents.
API#
Input message:
{
"targetFilePath": {
"pdf": "absolute file path",
"vlp_output": "absolute file path"
},
"responseFilePath": "absolute file path",
"operation": "table_image_inference"
}
Response is uploaded to the storage as specified in the responseFilePath field. The structure is as follows:
{
...,
"data": [
{
'pageNum': 0,
'bbox': {
'x1': 55.3407,
'y1': 247.0246,
'x2': 558.5602,
'y2': 598.0585
},
'uuid': '2b10c1a2-393c-4fca-b9e3-0ad5b774ac84',
'label': 'table',
'tableLines': [
{
'x1': 0,
'y1': 16,
'x2': 1399,
'y2': 16
},
...
],
'imageInfo': {
'height': 693,
'width': 1414
}
},
...
]
}
Installation#
git clone ssh://git@git.iqser.com:2222/rr/cv-analysis.git
cd cv-analysis
python -m venv env
source env/bin/activate
pip install -e .
pip install -r requirements.txt
dvc pull
Usage#
As an API#
The module provided functions for the individual tasks that all return some kind of collection of points, depending on the specific task.
Redaction Detection (API)#
The below snippet shows hot to find the outlines of previous redactions.
from cv_analysis.redaction_detection import find_redactions
import pdf2image
import numpy as np
pdf_path = ...
page_index = ...
page = pdf2image.convert_from_path(pdf_path, first_page=page_index, last_page=page_index)[0]
page = np.array(page)
redaction_contours = find_redactions(page)
As a CLI Tool#
Core API functionalities can be used through a CLI.
Table Parsing#
The tables parsing utility detects and segments tables into individual cells.
python scripts/annotate.py data/test_pdf.pdf 7 --type table
The below image shows a parsed table, where each table cell has been detected individually.

Redaction Detection (CLI)#
The redaction detection utility detects previous redactions in PDFs (filled black rectangles).
python scripts/annotate.py data/test_pdf.pdf 2 --type redaction
The below image shows the detected redactions with green outlines.

Layout Parsing#
The layout parsing utility detects elements such as paragraphs, tables and figures.
python scripts/annotate.py data/test_pdf.pdf 7 --type layout
The below image shows the detected layout elements on a page.
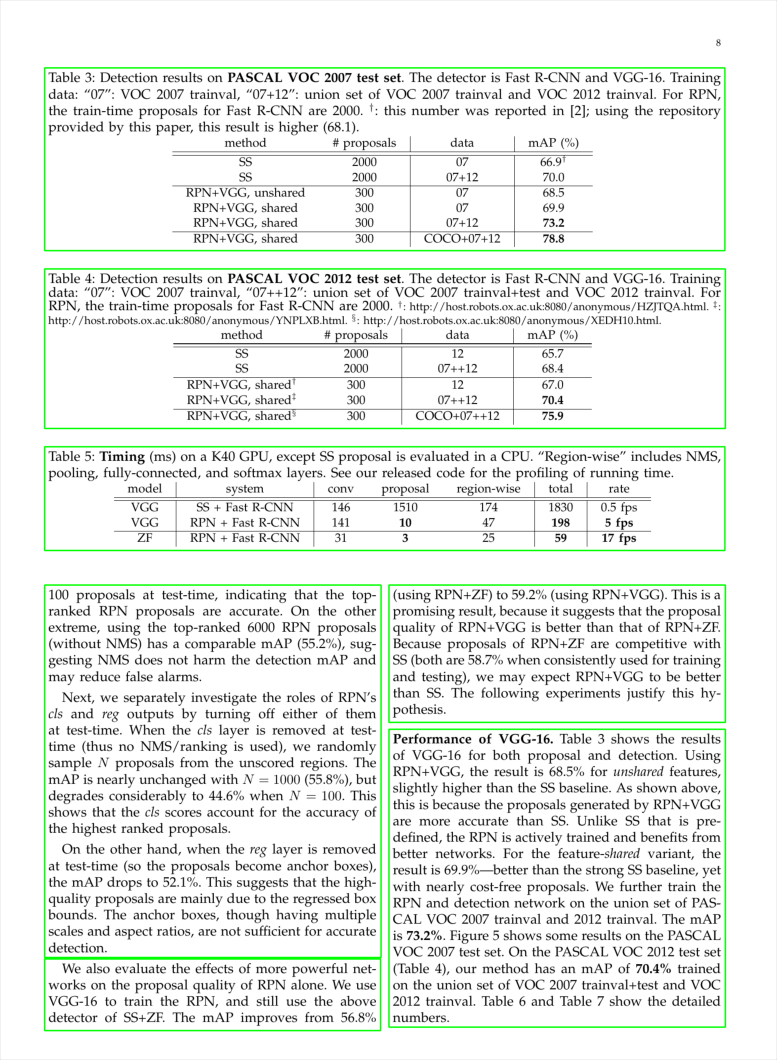
Figure Detection#
The figure detection utility detects figures specifically, which can be missed by the generic layout parsing utility.
python scripts/annotate.py data/test_pdf.pdf 3 --type figure
The below image shows the detected figure on a page.

Running as a service#
Building#
Build base image
bash setup/docker.sh
Build head image
docker build -f Dockerfile -t cv-analysis . --build-arg BASE_ROOT=""
Usage (service)#
Shell 1
docker run --rm --net=host --rm cv-analysis
Shell 2
python scripts/client_mock.py --pdf_path /path/to/a/pdf