Merge in RR/vidocp from text_removal to master
Squashed commit of the following:
commit b65374c512ce9ba07fa522d591c83db3de5d7d55
Author: Matthias Bisping <matthias.bisping@iqser.com>
Date: Sun Feb 6 01:03:12 2022 +0100
readme updated
commit 1c1f7a395a00fa505cf19e1ad87d8c34faa6ef5b
Author: Matthias Bisping <matthias.bisping@iqser.com>
Date: Sun Feb 6 01:00:46 2022 +0100
figure detection version 1 completed
commit f257660823ef8682e9fedda9921ad946ef2ade76
Author: Matthias Bisping <matthias.bisping@iqser.com>
Date: Sun Feb 6 00:37:03 2022 +0100
wip
commit 2e89b28f4a69da80570597c823b3b7a591788d0a
Author: Matthias Bisping <matthias.bisping@iqser.com>
Date: Sun Feb 6 00:23:56 2022 +0100
wip
2.2 KiB
Vidocp — Visual Document Parsing
This repository implements computer vision based approaches for detecting and parsing visual features such as tables or previous redactions in documents.
Installation
git clone ssh://git@git.iqser.com:2222/rr/vidocp.git
cd vidocp
python -m venv env
source env/bin/activate
pip install -e .
pip install -r requirements.txt
dvc pull
Usage
As an API
The module provided functions for the individual tasks that all return some kid of collection of points, depending on the specific task.
Redaction Detection
The below snippet shows hot to find the outlines of previous redactions.
from vidocp.redaction_detection import find_redactions
import pdf2image
import numpy as np
pdf_path = ...
page_index = ...
page = pdf2image.convert_from_path(pdf_path, first_page=page_index, last_page=page_index)[0]
page = np.array(page)
redaction_contours = find_redactions(page)
As a CLI Tool
Core API functionalities can be used through a CLI.
Table Parsing
The tables parsing utility detects and segments tables into individual cells.
python scripts/annotate.py data/test_pdf.pdf 7 --type table
The below image shows a parsed table, where each table cell has been detected individually.
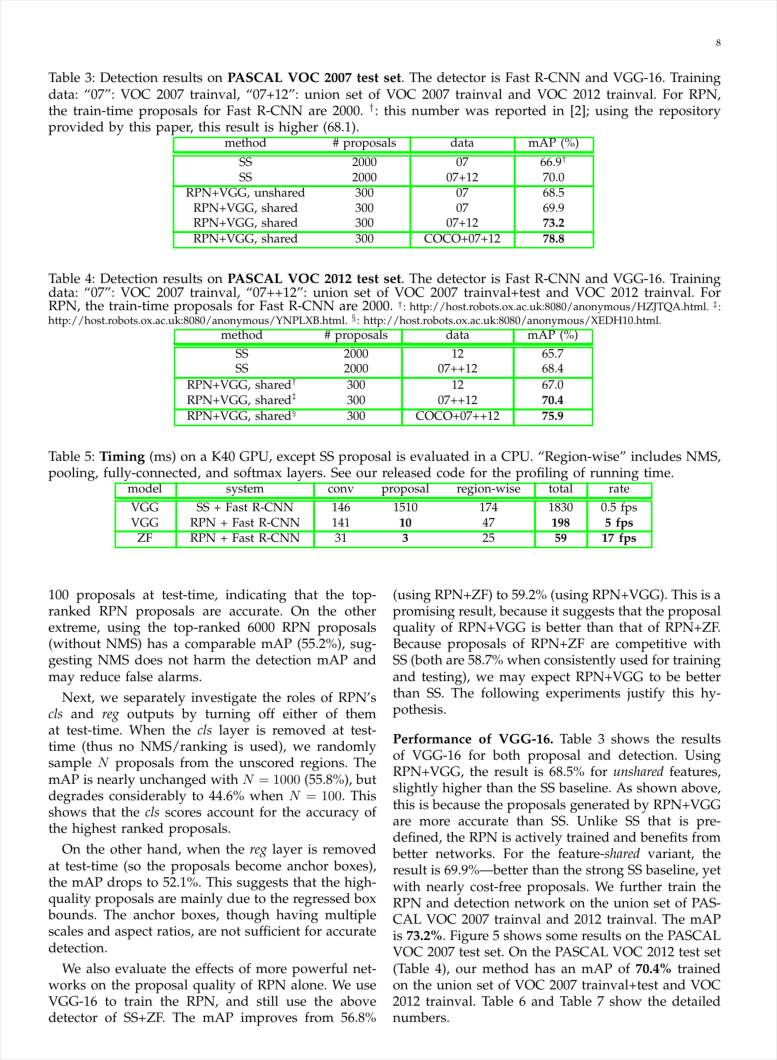
Redaction Detection
The redaction detection utility detects previous redactions in PDFs (filled black rectangles).
python scripts/annotate.py data/test_pdf.pdf 2 --type redaction
The below image shows the detected redactions with green outlines.

Layout Parsing
The layout parsing utility detects elements such as paragraphs, tables and figures.
python scripts/annotate.py data/test_pdf.pdf 7 --type layout
The below image shows the detected layout elements on a page.

Figure Detection
The figure detection utility detects figures specifically, which can be missed by the generic layout parsing utility.
python scripts/annotate.py data/test_pdf.pdf 3 --type figure
The below image shows the detected figure on a page.
